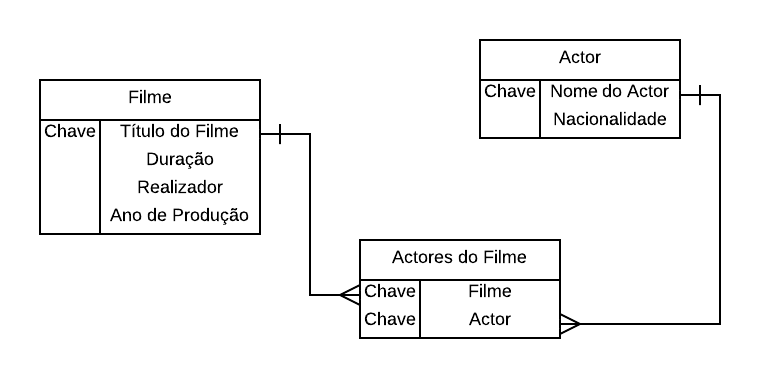
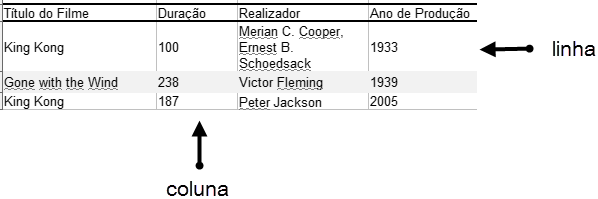
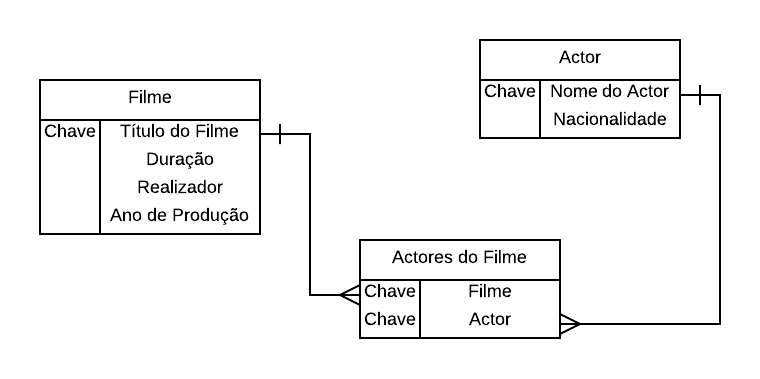
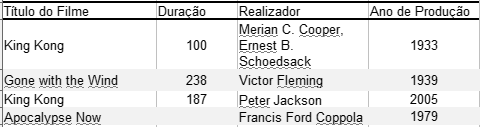
Para que cada linha de uma tabela tenha utilidade ela tem que ter uma identidade própria, quer dizer, deve ser diferente de todas as outras linhas. A distinção entre as linhas faz-se utilizando o conjunto mínimo de colunas que contenham os valores necessários e suficientes para tornar única cada linha. São os valores contidos nesse conjunto mínimo que distinguem as linhas entre si. No caso da tabela Filme da Figura 1 a coluna Título do Filme não é suficiente para distinguir os filmes entre si pois basta uma análise rápida para se encontrarem películas com a mesma denominação, e.g., “King Kong” aparece duas vezes e, caso fosse essa coluna identificadora então a tabela já teria linhas duplicadas.
 |
| Figura 1: Tabela Filme. |
Ora a duplicação de linhas é aquilo que nunca se quer numa base de dados relacional. Assim, a coluna Título do Filme não satisfaz a condição do conjunto mínimo, há que que juntar pelo menos mais uma para que se consiga atingir a unicidade das linhas. Isso depende sempre do contexto do processo de negócio que se está a analisar. No caso do esquema Cinema poderia aplicar-se optar-se entre duas colunas:
- Realizador;
- Ano de Produção.
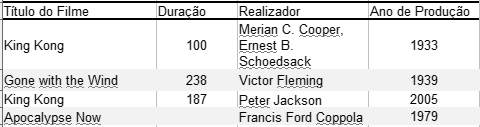
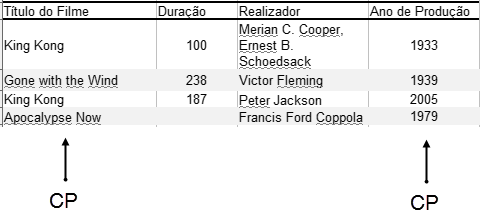
A opção 1) não é completamente satisfatória pois nada obsta a que um realizador trabalhe em duas películas distintas mas com a mesma denominação ao longo da sua vida. Já a opção 2) parece satisfazer a regra da unicidade pois é quase impossível que sejam produzidos dois filmes no mesmo ano e com o mesmo título. A regra da unicidade que se designa tecnicamente como chave primária (CP) será assegurada neste caso em simultâneo pelas colunas Título do Filme e Ano de Produção (Figura 2).
 |
| Figura 2: Tabela Filme com chave primária (CP). |
A unicidade é tecnicamente designada como a Integridade da tabela e, implica que em Filme possam existir muitos filmes denominados “King Kong” mas apenas um por cada ano de calendário. São possíveis muitos filmes em cada ano desde que tenham títulos diferentes. Já não é possível registar duas vezes a película “Apocalyse Now” para o ano de “1979”. Dai designar-se esta medida de segurança dos dados como uma Regra de Integridade.