Privilégio de INSERT | Oracle
Será que quando se dá o privilégio de INSERT numa tabela a um role isso implicitamente atribui a esse role a possibilidade de “ler” (SELECT) linhas da tabela?
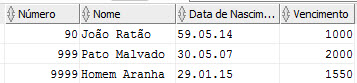
Para começar considere-se a tabela “Data” mostrada na Figura 1 (pertencente ao esquema IMDB) à qual se vai atribuir a autorização de inserção de linhas ao role sousa:
SQL> GRANT INSERT ON “Data” TO sousa;
 |
| Figura 1: Tabela Data. |
Agora falta testar a hipótese. Para tal entramos como sousa, e:
SQL> SELECT * FROM “Data”;
O resultado, como seria de esperar, é uma mensagem de erro:
ORA-01031: insufficient privileges
01031. 00000 – “insufficient privileges”
Apesar de em termos organizacionais não fazer grande sentido que alguém que pode registar dados não os consiga ler, de facto os privilégios nos sistemas de bases de dados relacionais cumprem com o objectivo com que foram pensados. O que pode ser facilmente demonstrado digitando o seguinte comando:
SQL> INSERT INTO “Data” (“Chave da Data”, “Descrição Completa da Data”,
“Descrição Abreviada da Data”, “Século”, “Data-SQL”)
VALUES (‘5’, ‘5 de Janeiro de 2017′, ’05/01/2017’, ‘XXI’,
TO_DATE(‘2017-01-05’, ‘YYYY-MM-DD’));